事業・プロジェクト紹介
公的ミクロデータ事業
高度信用リスクプロジェクト

プロジェクトの概要と想定される成果・目標
本研究は一般では公開されていない担保・保証・債務回収の情報を含む、地銀5行統合データベースを用いた期待損失率推計を扱い、汎用的で高精度な推計手法を開発・提案します。
これによって、期待損失率推計に対し統計的・機械学習的接近法を用いた推計手法が確立・実務利用され、その成果は信用リスク研究の発展、銀行の融資審査の高度化、金融行政の合理化、中小企業金融の円滑化に貢献することを目指します。
プロジェクトの背景
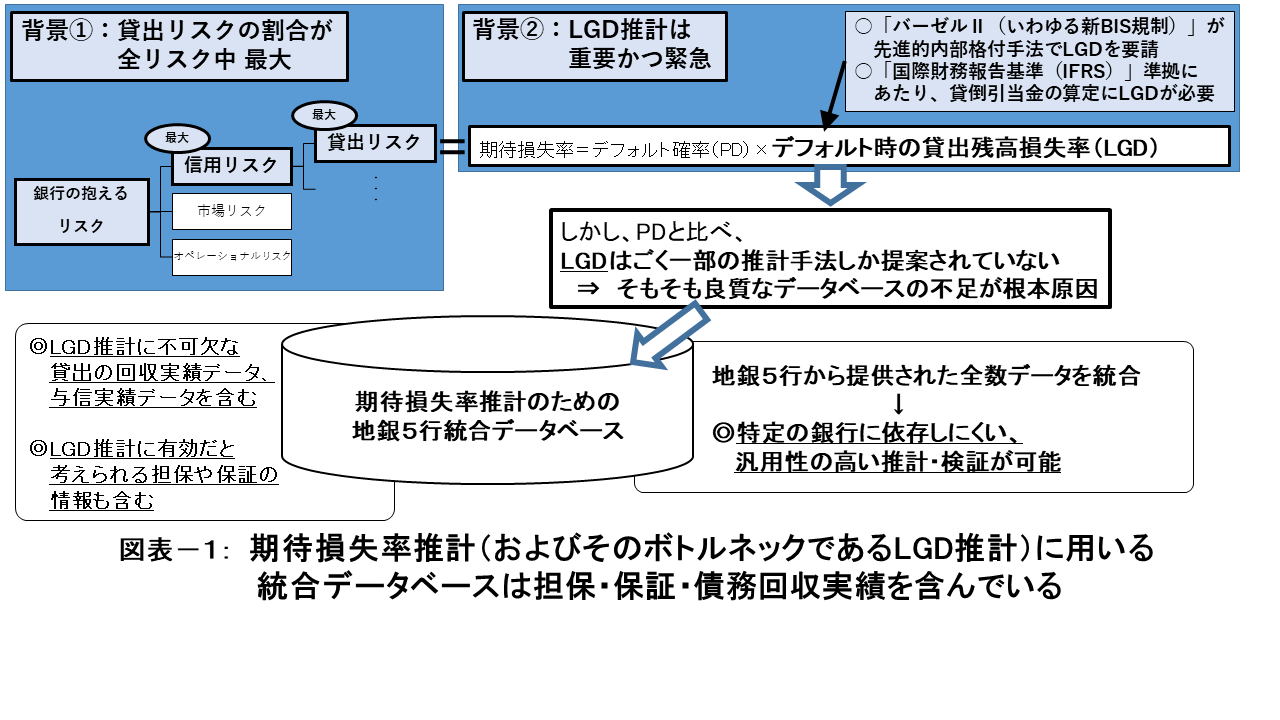
金融危機以降、間接金融の要である銀行はリスク管理の高度化が喫緊の課題となっています。銀行の抱える貸出リスクは、貸出先企業の期待損失率の推計によって補足されています。期待損失率の要因はデフォルト確率(Probability of Default; PD)とデフォルト時の貸出残高損失率(Loss Given Default; LGD)に分解され、特にLGDの推計はバーゼルⅡ(いわゆる新BIS規制)の先進的内部格付手法や国際財務報告基準(IFRS)の貸倒引当金算出において、重要な指標となっています。しかし、統合データベースの欠如が根本原因となり、LGD推計はごく一部の手法しか提案されていません(図表-1)。
プロジェクトでの研究・開発内容
2008年の金融危機から分かるように、社会における金融・経済の安定化のためには、銀行のリスク管理の精緻化が不可欠となっています。銀行の抱えるリスクには、主に信用リスク・市場リスク・オペレーショナルリスクの3つがあります。この3つのリスクの中で最も大きいリスクが信用リスクで、さらに銀行が抱える信用リスクでは、貸出リスクが一番大きいことが知られています。
そして、貸出リスクは主に貸出先企業の期待損失率によって補足され、それは(1) デフォルト確率(PD)と (2) デフォルト時の貸出残高損失率(LGD)に分解することができます。PDとは、一定の期間内(通常は1年間)に当該貸出先からの返済が滞る、つまり債務不履行状態に陥ってしまう確率のことです。
LGDとは債務不履行となった貸出先について、債務不履行発生時点の貸出残高のうち実際の損失に至る金額の割合のことを指しています。銀行はこれらの要素を精緻に推計することで、貸出債権のリスクを正確に把握する必要があります。
国際的に業務を展開している銀行の健全性を維持するための新たな自己資本規制であるバーゼルⅡでは、(A)標準的手法(外部格付を利用)と(B)内部格付手法で信用リスクを推定するよう記載されていて、(B)の内部格付手法は(B-1)PDのみ推計する「基礎的内部格付手法」と(B-2)PDとLGDの両方を推計する「先進的内部格付手法」に分類することができます。
しかし、このように銀行債権の信用リスクを推計しようとしたとき、銀行データの高い秘匿性により統合データベースの欠如が課題となります。特に、LGDの分析に不可欠な①「貸出の回収実績」(銀行の貸出によってどれだけ回収できたか(=損失が発生したか)の実績値)を含むLGD推計用のデータベースの不足が顕著になっています。
さらに、高精度なLGD推計手法を実務利用するためには②「担保」や「保証」などの有効だと思われる変数も含み ③結果が特定の銀行に依存しないよう複数の銀行のデータが統合されたデータベースが必要となります。この①~③をすべて満たすような日本唯一の信用リスク計量化用データベースのために、高度信用リスク統合データベースコンソーシアムが組成され、本研究で利用する期待損失率推計のための地銀5行統合データベースが構築されました。
統合データベースに対し、統計モデル・機械学習による最適な推計モデルを構築するため、下記サブテーマ(ア)~(エ)を解明に取り組んでいます。
(ア)バーゼルⅡ・IFRSへの対応
作成するモデルを実際に実務利用するためには、規制への対応が必要となる。各規制で定められたモデルの要件や課される制約について研究する。
(イ)最高の推計精度をもつモデル
推計精度を基準として、統計モデル・機械学習モデルの最先端モデルを網羅的に検討する。
(ウ)モデル・機械学習モデルの最先端モデルを網羅的に検討する。
数理統計学に基づく変数選択方法だけでなく、実務家の目線からチェックした方法や計算資源をフル活用した網羅的・全探索的な方法も用いて、モデルに最適な変数を見出す。
(エ)そのモデルの最適なパラメータ
最小二乗推定・最尤推定・ベイズ推定などを用いて、最適なパラメータを探求する。